Background
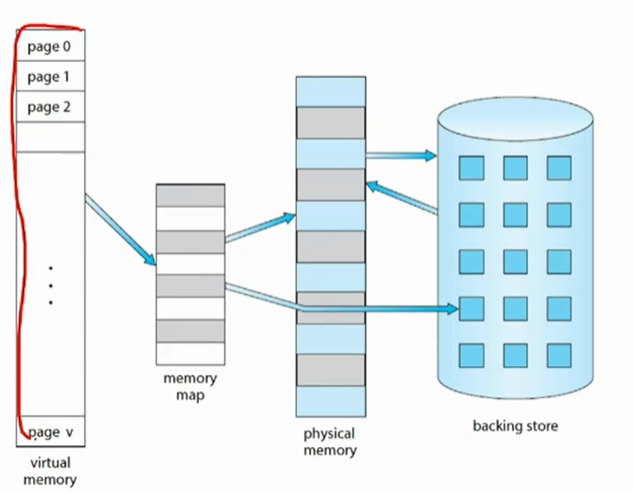
Virtual Memory
- 프로그램이 피지컬 메모리보다 클 경우에도 프로세스가 실행되도록 하는 테크닉
Virtual Address Space

Virtual Memory 장점
- 여러 프로세스가 page를 공유 할 수 있다.

Demand Paging
프로그램(하드웨어)가 실행되어 프로세스(메모리)로 바뀌는 내부동작
- 저장소에서 메모리로 올라간다
- 모든내용을 피지컬메모리에 올리지 않는다.(아두이노 등 제외)
- page로 분할 시키고 요청 될 때만 부분만 올린다(=demand paging)
Page Fault
- 프로세스의 일부(page)가 시작을 하기전 page table을 확인한다
- 프로세스의 원하는 페이지가 메모리에 있는지 확인한다
- 만약 invalid하다면, page를 메모리에 넣어줘야한다
- free-frame을 찾아서 second storage에서 넘겨준다
- page table을 reset을 통해 valid로 표시해준다
- 다시 인스트럭션을 그대로 실행해준다

Pure Demand Paging
요청을 하지 않으면 페이지를 가져오지 않기에, 첫번째 지시부터 바로 page fault를 일으킨다.
- 단점
- 3개의 page를 연속해서 실행할 때 3연속의 page fault를 일으키므로 비효율적이다
- Locality of Reference
- 코드 혹은 데이터의 집약성 때문에 한번 호출된 페이지에서 반복해서 작업이 일어나지, 계속 다른 페이지를 찾는 경우는 적다
Hardware Support to Demand Paging
- Page table - valid or invalid mark
- Secondary storages - swap space
Instruction Restart
paging out, in을 하는 중, page table이 관리가 안되면 꼬일 수 있다.
Demanding paging에 영향을 주는 요소
- TLB에 있을 확률
- page fault
- trap걸어주는 시간
- page를 읽는 시간
- 프로세스를 다시 시작하는 시간
Copy-on-Write
fork() or exec()처럼 같은 프로세스를 복사하는 경우는 첫번째 사진 처럼 같은 메모리를 공유하다가 write를 통해 작업공간이 달라지는 경우만 copy를 하는 개념이다

Page Replacement
Page Replacement 알고리즘이 필요한 이유
frame의 개수가 40개, 현재 동작하고 있는 프로세스가 가진 페이지가 60개더라도 Demand-Paging의 개념으로 모든 페이지를 올리지 않고 일부 페이지만 physical memory에 올림으로 여유 프레임을 확보할 수 있었다. 그렇지만 페이지수가 더 많은 프로세스 혹은 요구될 경우 기존에 있는 페이지를 교체해야하는 상황이 있기에 페이지 교체 알고리즘은 필요하다.
페이지가 교체되는 과정
secondary-storage에서 frame을 요구 → 기존에 있는 페이지 중에 희생자를 찾기 → 희생자를 빼고 해당 page table에 invalid 설정 → 요구된 page를 memory에 올리기 → 해당 page table에 valid 설정
페이지 요구와 교체가 중요한 이유
secondary storage I/O의 동작은 자원이 많이 들어가기에 조금의 환경 개선으로 많은 퍼포먼스를 얻을수 있다.
Page Fault를 카운트해서, 이 개수를 최소화 하는것이 목표
어떤 알고리즘을 써야할까?
간단하게FIFO알고리즘을 쓰면 효율적이지 않고, 크기가 커져도 일정수의 페이지 폴트가 반복되는 벨레이디의 모순 이라는 문제점이 있다.
OPT or MIN 이라고 불리는 미래 사건에 대해 알수 있다면, 가장 쓰이지 않는 페이지를 빼는것이 가장 효과적인데 이는 불가능하다.
OPT를 근사하게 구현
미래는 과거를 보면 알 수있다. 과거를 통해 미래를 예측해보자.
오랫동안 사용하지않은것은 미래에도 사용하지 않을것이다 → LRU(Least Recently Used)
LRU
locality에 근거해서 가장 오랫동안 사용하지 않은 프로세스는 앞으로도 안쓰이기에, 희생자로 지정하자 → OPT처럼 밸러디의 모순을 겪지 않을 수 있다.
자료구조가 복잡하기에, 하드웨어의 지원을 통해 (counter, stack)이 구현되면 좋은데 이것도 쉽지않다.
- Counter : 실행 횟수를 세서 안 쓰는거 고르기
- Stack : 가장 밑에 깔린놈 희생자로 고르기
- reference bit
- counter, stack이 힘드니까 쓰인거는 비트로 간단히 표현하여 최소한 안쓰인것을 고르지는 말자는 방법론
- second-chance : FIFO + reference bit
Allocation of Frames
Equal vs Proportional
프로세스 크기 별로 frame 더 많이 할당할 것인가에 대한 전략
Global vs Local
A라는 프로세스에서 page fault가 일어난다면 A프로세스가 올라가있는 프레임을 뺄지, 전체적인 기준에서 LRU 우선순위가 낮은 프로세스에서 뺄지에 대한 전략
Thrashing
Thrashing이 발생하는 이유
physical memory영역이 실질적으로 부족하게되면 잦은 Page Fault가 발생하게 된다.
invalid → valid로 요청하면서 wait큐로 들어가고 실행하게되는데 그 사이에 다시 invalid로 바뀌면서 실질적인 프로세스가 동작하지 않고 page fault만 반복하면서 CPU활용성이 심각하게 떨어지는 상태이다.
Working Set Model
Locality에 근거해 Page들의 모음인 working-set을 만든다.
working-set안에 위치한 프로세스가 동작 중이라면, working-set안에 있는 프로세스에는 fault를 내지 말자는 모델
'CS > OS' 카테고리의 다른 글
| [OS] I/O Systems & File-System Interface (0) | 2022.01.09 |
|---|---|
| [OS] Storage Management (0) | 2022.01.09 |
| [OS] Main Memory (0) | 2021.12.19 |
| [OS] Deadlocks (0) | 2021.12.16 |
| [OS] Synchronization Examples (0) | 2021.12.16 |



